Difference Between Regression And Classification In Machine Learning?
Content
- Let Us At First Discuss About Regression V
- Classification Vs Regression Models
- Key Differences Between Classification And Regression
- Regression Vs Classification In Machine Learning
However, in multi-label classification, there are multiple possible labels for each outcome. This is useful for customer segmentation, image categorization, and sentiment analysis for understanding text. To perform these classifications, we use models like Naive Bayes, K-Nearest Neighbors, SVMs, as well as various deep learning models. This is called binary classification (True/False, 0 or 1, / not ). In some cases, classification algorithms will output continuous values in the form of probabilities. Given the seemingly clear distinctions between regression and classification, it might seem odd that data analysts sometimes get them confused. However, as is often the case in data analytics, things are not always 100% clear-cut.
Regression notation is intuitive and this kind of analysis is sensitive to outliers in the data. Regression and classification can work on some common problems where the response variable is respectively continuous and ordinal. A classification algorithm is evaluated by computing the accuracy with which it correctly classified its input.
Too low, and you might be waiting forever for your model to converge on the best set of weights; too high, and you risk missing the best set of weights because the model would not converge. This iterative approach is repeated until a minimum error is reached, and gradient descent cannot minimize the cost function any further. Based on the slope, gradient descent updates the values for the bias and the set of weights, then reiterates the training loop over new values . Imagine that you’re tasked to predict whether or not a client of your bank will default on their loan repayments. The first thing to do is construct a dataset of historic client defaults. Finally, let’s check to see how the classifier performed by importing some metrics and checking the predicted values against the actual values.
If the predicted distribution function tends to follow the actual distribution function, we say that model is learning accurately. If you are just starting out in machine learning, you might be wondering what the difference is between regression and classification. This post will show you how they differ and how they work. FM can be used for regression and optimization criterion is mean square error.
Let Us At First Discuss About Regression V
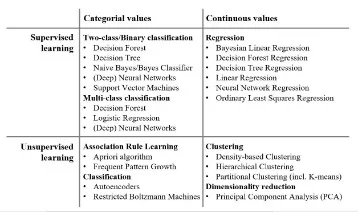
Both of them fall under the umbrella of supervised learning algorithms. This means that the training data that they learn from includes the output values they are trying to learn to predict. If the data is not labeled then it is called an unsupervised machine learning problem and a clustering algorithm will be used instead. Some algorithms can be used for both classification and regression with small modifications, such as decision trees and artificial neural networks. Some algorithms cannot, or cannot easily be used for both problem types, such as linear regression for regression predictive modeling and logistic regression for classification predictive modeling.
Support Vector Machines learn what class examples belong to by fitting a line between the data points and maximizing the margin on either side of that line based on their y-labels. Hard margin SVMs do not allow any data points to fall within the margin but soft margin SVMs do. Allowing for some data points to fit within the margin helps to avoid overfitting.
Classification Vs Regression Models
Classification models include logistic regression, decision tree, random forest, gradient-boosted tree, multilayer perceptron, one-vs-rest, and Naive Bayes. Regression, in machine learning, is where you train an algorithm to predict a continuous output based on a set of features . Currently in spark.ml, only a subset of the exponential family distributions are supported and they are listedbelow.
Choosing an appropriate regression technique, again, highly depends on the data at hand. Questions we may want to answer is if we have constant variance among the residual.
Classification predictive modeling problems are different from regression predictive modeling problems. There are many ways to estimate the skill of a regression predictive model, but perhaps the most common is to calculate the root mean squared error, abbreviated by the acronym RMSE. A problem with two classes is often called a two-class or binary classification problem. Questions like this are a symptom of not truly understanding the difference between classification and regression and what accuracy is trying to measure. One of the key elements in choosing a method is having a sensitive accuracy scoring rule with the correct statistical properties. ROC AUC is preferable to accuracy, especially in multiclass prediction settings or when we have a class imbalance problem.
Key Differences Between Classification And Regression
It is a special case of Generalized Linear models that predicts the probability of the outcomes. Use the familyparameter to select between these two algorithms, or leave it unset and Spark will infer the correct variant. Firstly, it may seem logical to assume that regression and classification problems use different algorithms. In fact, many algorithms, such as decision tree and random forest can be adapted for both classification and regression tasks.
Production data science means spending more than 80% of your time on data collection and cleaning. If you want to speed up the entire data pipeline, use software that automates tasks to give you more time for data modeling. The target variable takes one of two possible categorical values. For example, spam vs. not spam, 0 vs. 1, dog vs. not dog, etc. For example, we would input the email subject line (“A Nigerian prince needs your help”) into the model with the accompanying class (“spam”).
Principally both of them have one common goal i.e. to make predictions or take a decision by using the past data as underlined foundations. There is one major difference as well; classification predictive output is a label and for regression its a quantity. It just so happens that they can do more than categorising the input data. Can call classification as sorting and regression as connecting technique as well. The target variable takes one of three or more possible categorical values.

Here the probability of event represents the likeliness of a given example belonging to a specific class. The predicted probability value can be converted into a class value by selecting the class label that has the highest probability. Classification is one of the parts of machine learning, dedicated to solving the following problem. There are many objects that are divided into classes in some way. The task is to build an algorithm that can classify an arbitrary object from the original set. One-dimensional, or simple linear regression, is a technique used to model the relationship between one independent input variable, i.e. the function variable, and the output dependent variable. A classification problem is when the output variable is a category, such as “red” or “blue” or “disease” and “no disease”.
Machine Learning Approaches To Logistic Regression
A predicted probability can be converted into a class value by selecting the class label that has the highest probability. The output variables are often called labels or categories.
- A classification algorithm can have both discrete and real-valued variables, but it requires that the examples be classified into one of two or more classes.
- Classification methods simply generate a class label rather than estimating a distribution parameter.
- These algorithms are called supervised learning algorithms.
Classification algorithms work by using input variables to create a mapping function. These data contain observations whose classifications are already known and so the algorithm can use them as a guide. This helps determine the output variables with varying degrees of accuracy. This tree-based algorithm includes a set of decision trees which are randomly selected from a subset of the main training set. The random forest classification algorithm aggregates outputs from all the different decision trees to decide on the final output prediction, which is more accurate than any of the individual trees. On the other hand, classification algorithms attempt to estimate the mapping function from the input variables to discrete or categorical output variables . Conclusion– We have elaborated our earlier posts on Machine learning algorithmsfor understanding classification and regression techniques under supervised learning.
Represents the percentage of correctly classified samples. An accuracy score of 90% would tell us that our logistic regression model correctly classified 90% of all examples. Because of the ease of computation, logistic regression can be used in online settings, meaning that the model can be retrained with each new example and generate predictions in near real-time.